입력
수정
캘리포니아 대학, 강화 학습으로 앤드루스-커티스 추측 일부 사례 단순화 난제 증명이나 예측이 아닌 탐색 방식 개선과 교육적 활용에 의의 성과 범위를 명확히 하고 과장된 해석은 경계 필요
본 기사는 The Economy 연구팀의 The Economy Research 기고를 번역한 기사입니다. 본 기고 시리즈는 글로벌 유수 연구 기관의 최근 연구 결과, 경제 분석, 정책 제안 등을 평범한 언어로 풀어내 일반 독자들에게 친근한 콘텐츠를 제공하는 데 목표를 두고 있습니다. 기고자의 해석과 논평이 추가된 만큼, 본 기사에 제시된 견해는 원문의 견해와 일치하지 않을 수도 있습니다.
최근 일부 언론은 강화 학습(Reinforcement Learning, 시행착오를 반복하며 보상을 극대화하는 행동 방식을 기계가 학습하도록 하는 기법)이 60년 넘게 풀리지 않은 앤드루스-커티스 추측(Andrews–Curtis conjecture)을 해결했다고 보도했다. 수학계의 난제를 인공지능(AI)이 풀었다는 과장된 해석이 뒤따랐다.
실제 연구는 캘리포니아 공과대학 연구팀이 주도했다. 연구진은 강화 학습의 시행착오 학습을 기반으로, 여러 단계를 묶어 처리하는 압축 기법을 도입해 수십 년간 탐색이 막혀 있던 일부 사례를 단순화하는 데 성공했다. 그러나 성과는 제한적이었다. 난도가 높은 잠재적 반례까지 해결한 것은 아니며, 상대적으로 쉬운 사례에 국한됐다.
연구팀은 논문 요약문에서 이번 성과가 추측을 증명하거나 반박한 것이 아님을 분명히 했다. 가장 난도가 높은 수백만 단계 문제에는 접근조차 하지 않았으며, 이 방법으로 금융시장 위기나 감염병 같은 현실 세계 사건을 예측할 수 없다고 강조했다. 금융 규제기관들 역시 인공지능의 금융 예측 능력이 여전히 취약하다고 지적한다.
학습 과제에서 교육 도구로
이번 연구는 ‘유도 탐색’을 단순한 예측 문제가 아니라 장기적 관점을 요구하는 학습 과제로 제시했다. 퍼즐을 단계적으로 풀어가는 과정에서 알고리즘이 짧은 보상 구조에 약점을 드러낸다는 점과, 여러 단계를 묶는 압축 기법이 이를 보완할 수 있다는 점을 보여줬다.
이 관점은 대학의 교육과정 설계에도 의미가 있다. 이번 프로젝트를 컴퓨터과학 실습으로 다루면, 학생들은 알고리즘적 창의성을 경험하면서도 실제 적용 가능성과 한계를 구분할 수 있다.
연구 성과를 평가하는 기준도 분명하다. 중요한 것은 언론의 화려한 수사가 아니라, 기존 방법보다 나은 결과를 냈는지, 계산 자원을 투명하게 공개했는지, 다른 연구자들이 재현할 수 있는지다. 이번 연구는 범용 강화 학습보다 단순 탐색이 더 좋은 성과를 내는 경우가 있음을 확인했고, 적은 자원으로도 재현할 수 있는 실험임을 강조했다. 독립 연구자들도 이를 검증해 교육 현장에서 활용할 수 있는 기준을 마련했다.
무엇을 했고, 무엇을 하지 않았는가
연구의 기술적 핵심은 단순하다. 연구팀은 앤드루스-커티스 추측 사례를 대규모 의사결정 문제로 구성해 실험했다. 근접 정책 최적화(Proximal Policy Optimization, PPO) 방식은 성과가 미미했지만, 문제 특성을 반영한 단순 탐색 기법은 더 나은 결과를 냈다. 여기에 두 개의 학습 모듈을 활용해 여러 단계를 묶어 처리하는 압축 기법을 결합하자, 기존에 막혀 있던 사례들을 풀 수 있었다.
논문은 두 가지 점을 강조한다. 첫째, 이번에 얻은 해법은 수천 단계 수준으로, 수학자들이 예상한 극도로 복잡한 경우보다 훨씬 짧다. 둘째, 계산 자원을 의도적으로 제한해 다른 연구자들도 쉽게 재현할 수 있도록 했다. 이는 재현 가능성을 중시한 과학적 태도다. 그러나 이번 연구는 추측을 증명하지 못했으며, 새로운 예측 능력을 제공하지도 않았다. 특정 영역을 더 자세히 관찰할 수 있는 도구를 제시한 것에 불과하다.
영국 리버풀대 연구팀도 별도의 연구를 통해 자동 정리 증명기를 활용, 밀러-슈프(Miller–Schupp) 제시를 8,634단계로 단순화했지만 74일과 56GB 메모리가 필요했다. 이는 집요한 탐색의 성과일 뿐, 새로운 예측 기법이나 근본적 증명은 아니었다. 전문가들은 이런 작업이 대학원 수준의 고급 과제에 가깝다고 평가한다.
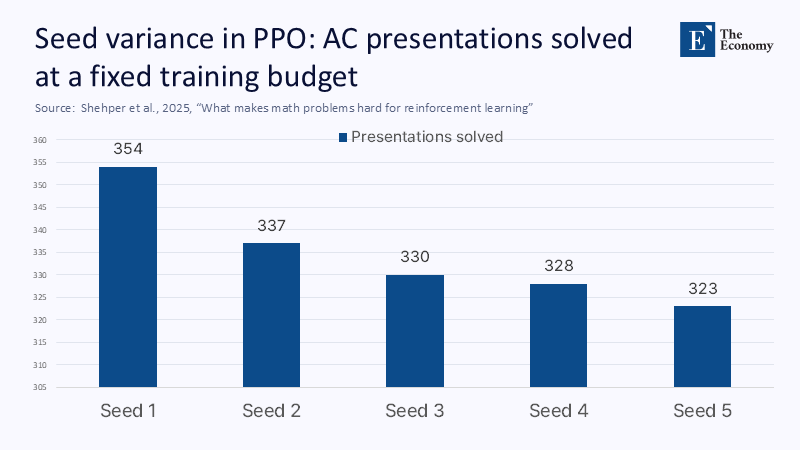
주: 시드 번호(X축), 해결된 과제 수(Y축)
무차별 대입이 아닌 안내된 탐색
이번 방식을 단순히 무차별 대입(Brute force)이라고 보기는 어렵다. 탐색 범위를 넓히고 효율적으로 반복했다는 점에서는 맞지만, 무작정 모든 경우를 나열한 것은 아니기 때문이다. 연구팀은 기존 탐색 기법과 성능을 비교하며, 전통적인 너비 우선 탐색(Breadth-First Search, BFS)이 일정 단계 이상에서는 성능이 급격히 떨어진다는 점을 확인했다. 이어 학습 과정을 단계적으로 설계하고 여러 동작을 묶는 기법을 도입해 이 한계를 보완했다.
강화 학습은 추측 자체를 이해한 것이 아니라, 탐색 비용을 줄이고 분산시키는 정책을 학습한 것이다. 연구팀은 코드를 공개해 작은 연구실에서도 재현할 수 있도록 했고, 단순 탐색이 범용 강화 학습보다 나은 성과를 내는 경우도 제시했다. 학생들에게 이런 차이를 직접 실험하게 하는 것은 교육적으로 큰 의미가 있다.
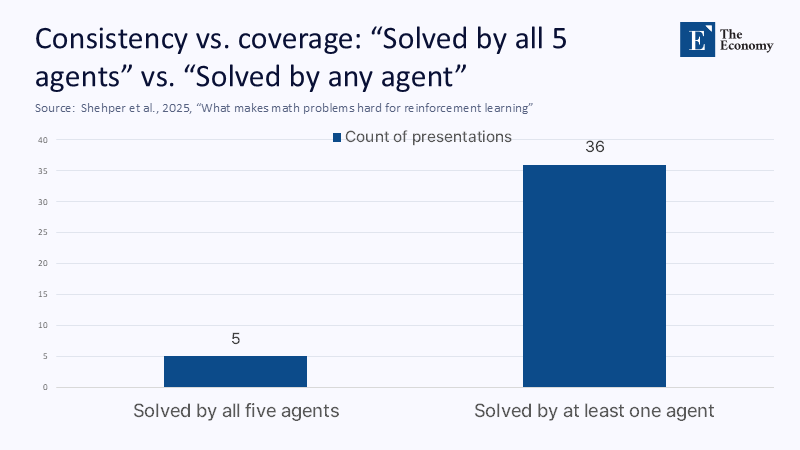
주: 종류- 5개 에이전트 해결, 단일 에이전트(X축), 해결된 발표 수(Y축)
왜 ‘예측’으로 과장되는가
일부 언론과 연구자들은 종종 수학 난제 풀이와 금융 위기 예측을 같은 맥락에서 비유하지만, 이는 성격이 전혀 다르다. 수학 문제는 규칙이 고정됐지만, 금융 위기 같은 현실 문제는 변수가 끊임없이 변한다. 국제 금융기관들도 같은 입장이다. 금융안정위원회(FSB)는 인공지능이 불확실성과 불투명성을 키워 위험 평가를 더 어렵게 한다고 경고했고, 유럽중앙은행(ECB)은 부정확한 예측이 위험 관리 기능을 약화시킬 수 있다고 밝혔다. IMF는 초고속 거래에서 AI가 변동성을 확대할 수 있다고 지적했다. 이는 혁신에 반대한 것이 아니라, 증거 없는 과장을 경계한 것이다.
실증 연구도 이를 뒷받침한다. 2024~2025년 발표된 메타분석들은 AI가 갈등이나 위기를 예측할 때 통계적으로 의미 있는 결과를 내더라도, 환경이 바뀌면 실제 효용으로 이어지지 않는다고 지적했다. 각종 예측 대회에서도 인간 예측 전문가들이 AI보다 더 정확한 결과를 내는 경우가 많았다. 따라서 교육에서는 강화 학습뿐 아니라 통계학, 인과 추론, 의사결정 이론을 함께 가르쳐야 한다. 다양한 접근법을 병행해야 인공지능의 한계와 가능성을 균형 있게 이해할 수 있다.
교실과 소통에서 필요한 변화
수학교육은 컴퓨터과학을 핵심 축으로 통합할 필요가 있다. 미국 산업응용수학회(Society for Industrial and Applied Mathematics, SIAM)가 주관한 학술 패널에서도 수학·인공지능·고성능 컴퓨팅의 접점이 강조됐다. 교과과정에는 연구 자료를 직접 재현하는 과제를 포함하고, 계산 과정을 결과와 연결해 해석하는 훈련이 뒷받침돼야 한다.
대학의 대외 소통 방식도 달라져야 한다. 연구가 실제로 할 수 없는 부분은 홍보 과정에서도 그대로 밝혀야 하며, 연구 내용을 비유로 설명할 때는 오해가 생기지 않도록 그 한계를 반드시 함께 제시해야 한다. 캘리포니아 공과대학이 성과의 범위를 분명히 밝힌 사례는 참고할 만하다.
현장의 회의론과 교육적 활용
AI 성과에 대한 회의적 시각은 학계 밖에서도 널리 퍼져 있다. 2023년 한 포럼에서는 현대 AI를 “단순한 기계학습”으로 규정하며, 겉으로 화려해 보이는 결과가 실제 이해로 오인된다고 비판했다. 이런 평가는 다소 냉소적으로 보일 수 있지만, 교육적으로는 의미가 있다. 계산을 과학적 변수로 다루고, 예측과 설득을 구분하며, 비교 실험을 중시하는 태도를 기를 수 있기 때문이다.
일부 비평가가 이번 연구를 “공대생 수준의 과제”라고 평가하더라도, 교육 현장은 이를 방어할 필요가 없다. 오히려 학생들에게 곡선을 직접 재현하게 하고, 보상 구조가 결과에 어떤 영향을 미치는지 실험하게 하는 것이 바람직하다. 비판을 수업으로 전환할 때, 회의론은 학습 효과를 높이는 자원이 될 수 있다.
연구 성과는 교육용 도구
이번 연구에서 가장 중요한 점은 해결된 사례의 숫자가 아니다. 실제 성과와 언론이 덧씌운 해석 사이의 차이다. 수천 단계에 걸친 문제 해결은 꾸준한 탐색과 구조화된 접근의 결과일 뿐, 사회적 사건을 예측할 수 있다는 증거는 되지 않는다.
교육적 의미는 분명하다. 장기 최적화를 실습할 수 있는 환경을 제공하고, 탐색 성과를 객관적으로 비교할 수 있는 기준을 마련했으며, 계산 자원과 코드 공개가 과학적 방법의 일부임을 확인할 수 있었다.
정책적 시사점도 뚜렷하다. 컴퓨터 기반 수학 교육에 대한 투자를 확대하고, 연구 성과를 대외적으로 알릴 때는 적용 범위와 한계를 분명히 밝혀야 한다. 수학적 탐색 성과를 경제나 사회 예측으로 확대 해석하는 주장은 근거 없는 과장으로 다뤄져서는 안 된다. 학생들에게 실제 성과와 적용 가능성을 구분하는 훈련을 제공해야, 연구의 재현성과 교육적 가치를 살리면서도 불필요한 기대를 막을 수 있다.
본 연구 기사의 원문은 When "Discoveries" Are Just Big Labyrinths: What an AI Exercise Teaches Us in Pure Math for Education, Evidence, and Hype | The Economy를 참고해 주시기 바랍니다. 2차 저작물의 저작권은 The Economy Research를 운영 중인 The Gordon Institute of Artificial Intelligence에 있습니다.