4,000개 언어 인식 가능한 ‘MMS 모델’ 오픈소스 공개한 메타, OpenAI 집중 겨냥
대규모 다국어 음성인식 AI 모델 무료로 공개한 메타 MMS 통해 훈련된 AI 모델, 단어 오류율 절반으로 낮춰 챗GPT 등장 이후 과열된 AI 시장, 메타 전략 효과 있을까

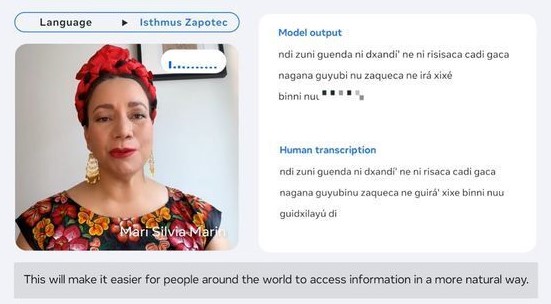
메타가 4,000개의 언어 식별이 가능하고, 1,000개가 넘는 언어를 음성-텍스트로 상호변환할 수 있는 ‘대규모 다국어 음성인식(Massively Multilingual Speech, MMS)’ 인공지능(AI) 모델을 오픈소스로 공개한다고 24일 밝혔다. 최근 생성형 AI에 많은 경쟁사가 진입하고 있는 만큼 인식 가능 언어 숫자를 크게 늘리고 이를 외부에 공개해 시장 선점 효과를 누리겠다는 전략이다.
1,107개 언어 상호변환 가능, 괴물 AI의 등장
현재 지구상에 사용되는 언어의 수는 7,000개가 넘지만, 기존의 음성인식 모델은 이 중 100여 개의 언어만 음성인식 및 음성-텍스트 상호 변환을 지원한다는 한계가 있었다. 메타가 이번에 발표한 MMS는 이전 모델과 다르게 1,107개 언어를 음성에서 텍스트로 또는 텍스트에서 음성으로 변환하고, 음성으로 인식 가능한 언어의 수도 4천 개가 넘는다는 점에서 유의미하다.
기존의 모델 대비 MMS를 통해 훈련된 AI 모델이 우수한 성능을 보인 것 역시 두드러진다. 메타 모델 분석 결과에 따르면 음성으로 변환할 언어의 수를 61개에서 1,107개로 약 18배 늘렸음에도 단어 오류율은 0.4%만 증가했다. 챗GPT 개발사 OpenAI의 음성인식 모델 ‘위스퍼(Whisper)’와 비교한 결과 역시 주목할 만하다. MMS 데이터를 통해 학습 시킨 메타의 모델은 위스퍼와 달리 단어 오류율을 절반으로 줄이면서도 11배 더 많은 언어를 인식하고 처리할 수 있는 것으로 나타났다.


성경에서 해결책 찾은 메타, OpenAI 본격 추격
MMS 모델 훈련 당시 음성인식 AI 모델의 학습용 언어 수집 과정에서 난관에 봉착한 메타는 신약 성경에서 그 실마리를 찾았다. 약 4,000개 이상의 언어로 번역돼 있는 데다 오디오 데이터까지 보유한 신약 성경의 특징을 활용한 것이다. 이를 통해 언어당 평균 32시간의 데이터를 제공하는 신약 성경 오디오 및 텍스트 데이터 세트를 제작해 MMS 모델을 훈련시켰다. 여기에 더해 자사의 연구 결과를 활용해 1,400개 이상의 언어로 구성된 약 500,000시간의 음성 데이터를 구축하고 MMS 모델을 교육하는 데 활용했다.
한편 일각에서는 이번 MMS 모델과 코드를 오픈 소스로 공개한 것이 OpenAI를 따라잡기 위한 전략이라는 분석이 나온다. 지난 4월 루크 세르나우(Luke Sernau) 구글 수석 엔지니어는 메타가 지난 2월 발표한 대규모언어모델(LLM) ‘라마(LLaMA)’에 주목했다. 라마가 외부에 공개된 이후 개발자들 사이에서 이를 활용한 여러 모델이 개발되자 메타가 기술 개발에 탄력을 받았다는 주장이다.

메타의 ‘오픈소스 전략’, 경쟁사들 상대로 우위 선점 가능할까
최근 구글과 OpenAI가 LLM을 개발하면서 시장을 주도하는 가운데, 메타는 오픈소스 전략으로 차별점을 뒀다. 실제로 구글과 OpenAI는 약 5,400억 개 이상의 매개변수를 가진 LLM을 통해 시장에서 우위를 점하고 있지만 상당한 비용이 발생하는 데다 대규모 컴퓨팅 인프라가 필요한 만큼 슈퍼컴퓨터 없이는 AI 모델을 단시간 내에 구현할 수 없다는 단점을 가진다.
반면 메타는 소스 코드 및 모델을 외부에 공개하며 빠르게 시장 내 점유율을 확보하고 있다. 실제로 메타가 외부 연구자나 개발자들이 자유롭게 활용할 수 있도록 라마의 소스 코드를 공개한 이후 ‘알파카’, ‘비쿠냐’ 등 많은 소형언어모델(sLLM)이 등장하며 유의미한 실적을 보였다. 업계 관계자는 “라마는 약 70억 개의 매개변수를 기반으로 개발돼 AI 모델을 단시간 내에 구현할 수 있는 게 특징”이라며 “다양한 개발자들이 파인튜닝을 통해 맞춤형 AI 모델을 개발할 수 있는 토대를 제공했다”고 분석했다.
문제는 시장에 경쟁자들이 빠르게 증가하고 있다는 점이다. 지난해 11월 전 세계를 떠들썩하게 만든 챗GPT의 등장 이후 많은 기업이 생성형 AI 패권 경쟁에 뛰어들면서 기술 확보에 박차를 가하는 추세다. 구글은 GPT-4에 대항할 차세대 LLM인 ‘팜2(PaLM2)’를 지난 10일 발표했으며, 한때 AI계 선두 주자로 불렸던 IBM도 ‘왓슨X’를 발표하며 재도약에 나서고 있다. 마이크로소프트 역시 ’MS 365 코파일럿’을 출시하며 생성형 AI 경쟁에 불씨를 지폈다. 스타트업부터 글로벌 빅테크 기업까지 AI 시장에서 주도권을 확보하기 위해 총력전을 벌이는 상황에서 과연 메타의 전략이 실효를 거둘 수 있을지 업계의 시선이 쏠린다.